Multi-replica HA. The seven phases that get loomcycle close to v1.0
The screenshot below is the thing that wasn't possible a month ago. Two loomcycle binaries, one shared Postgres, one bearer token, one Web UI - three runs for user alice in flight simultaneously, each tagged with the replica that's actually executing it, and a fourth that completed in 2.4 seconds open on the right with its transcript visible.
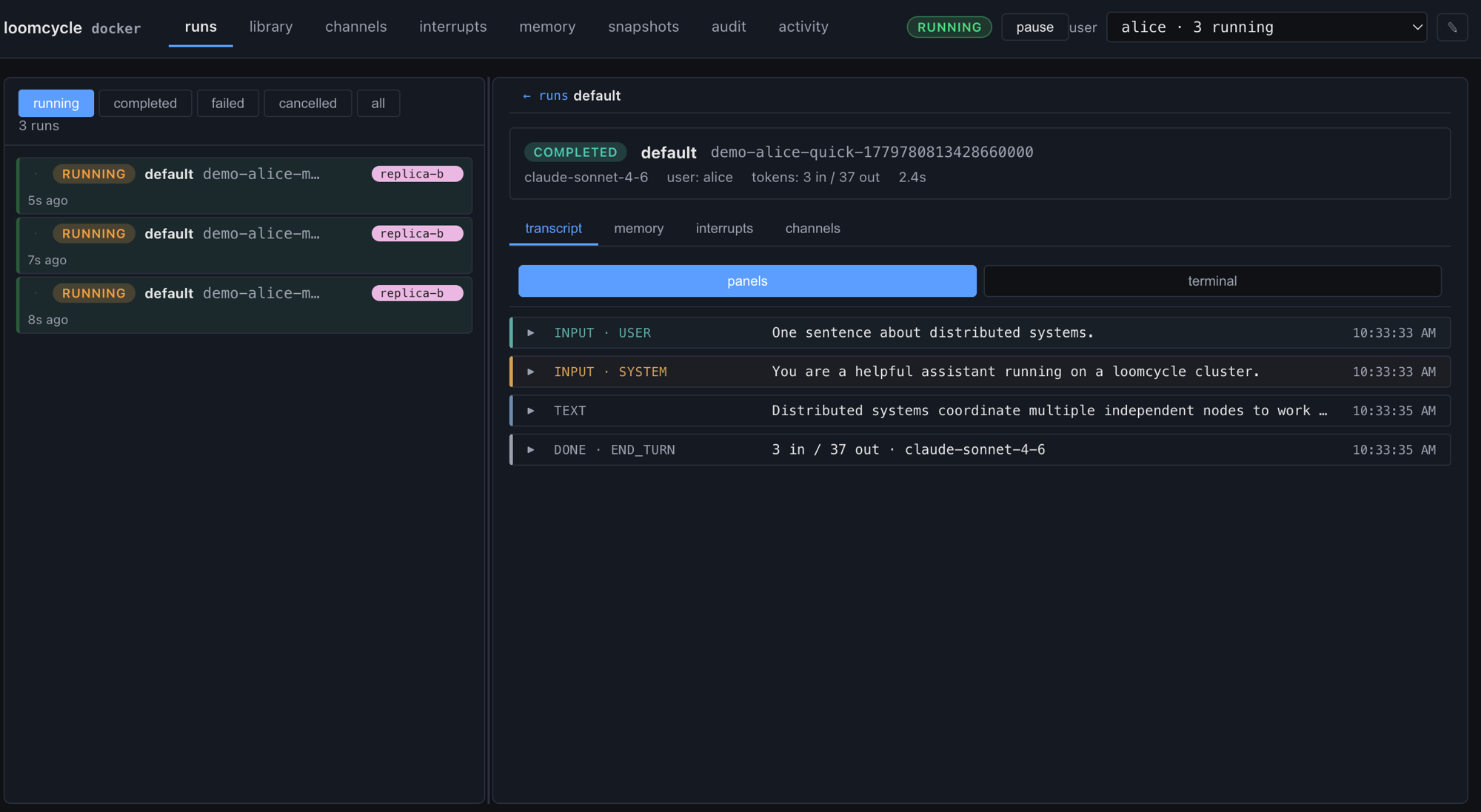
replica-b; a fourth (completed in 2.4 s) is open on the right with its full transcript visible. The replica-b chip is the new bit - the visible artefact of cluster mode. The 3 in alice · 3 running reflects the same count the cluster-wide run-admit semaphore (v0.12.1) is tracking - the per-user quota counter is now one number across every replica.Single-process loomcycle has been production for months. Multi-replica was the v1.0 commitment from the start of the v0.12.x line. Seven phases, four weeks, ~5,000 LOC across the runtime + a docker-compose demo + an operator runbook. This is not v1.0 yet - load testing, longer soak runs, and a hardening pass against the cluster invariants are still ahead. But the runtime now has every architectural piece v1.0 promises, and the demo stack lets anyone reproduce the screenshot in under five minutes.
The seven phases
Each phase landed as its own release (v0.12.0 through v0.12.5, plus the v1.0 capstone PR). Single-replica deployments - anyone with LOOMCYCLE_REPLICA_ID unset - got zero behaviour change across every phase. Cluster mode activates by setting the env var.
| Phase | Released as | What lands |
|---|---|---|
| 1 · Foundation | v0.12.0 | LOOMCYCLE_REPLICA_ID + replicas heartbeat table + the coord.Backplane interface + Postgres LISTEN/NOTIFY implementation + SQLite refuses to start in cluster mode + runs.replica_id column. |
| 2 · Per-user fairness | v0.12.1 | The v0.10.1 in-process semaphore lifts to a cluster-wide user_quotas table. Atomic UPDATE … SET active = active+1 WHERE active < cap. One user can't starve another across the whole cluster, not just one replica. |
| 3 · Cancel + status | v0.12.2 | Cancel broadcasts on the loomcycle.cancel channel; every replica subscribes; only the owning replica acts. 5-second ack timeout. Status queries on the "wrong" replica resolve from the DB row. |
| 4 · Pause / Resume + bus fanout | v0.12.3 | Cluster-wide pause via a singleton runtime_state row + 1-second cache + LISTEN/NOTIFY invalidation. The RunState SSE stream and the Channel pub/sub bus fan out across replicas the same way. |
| 5 · Singleton sweepers + replicas TTL | v0.12.4 | Every TTL sweeper wraps in pg_try_advisory_lock so only one replica per tick does the work. New ReplicasSweeper reaps dead-replica rows after 90s + marks their owned runs as failed + decrements the leaked user-quota slots. |
| 6 · Session lock + hook registry → DB | v0.12.5 | The session-continuation lock moves from in-process map to pg_try_advisory_lock(hash(session_id)) on a pinned pgxpool connection. Concurrent continuations of the same session across replicas both get 409. Hook registry gains a DB-backed wrapper with backplane-driven cache invalidation so a hook registered on replica A reaches replica B. |
| 7 · Hardening capstone | v1.0 PR | Docs (MULTI-REPLICA.md), the process_samples.replica_id column for per-replica observability, the operator-cookbook fragments that the Helm chart will eventually consume. |
What's shared via Postgres, what stays per-replica
The locked architectural decision at the start of the line was Postgres LISTEN/NOTIFY as the only backplane in v1.0. No Redis dependency. The interface (coord.Backplane) keeps Redis as an optional future implementation if scale ever demands it, but the 2-10 replica range that's the actual v1.0 target sits well inside LISTEN/NOTIFY's headroom and zero-new-infra is its own load-bearing feature.
Shared via Postgres: replica heartbeats, run state, cancel broadcasts, pause/resume signals, RunState SSE fanout, Channel publish fanout, per-user quota counters, dead-replica reaping, every singleton sweeper, the session-continuation lock, the hook registry.
Per-replica by design: MCP stdio child processes (resource scaling, not correctness), the local Anthropic-OAuth-dev token store (operator-machine artefact; documented), snapshot file restoration (replica-local), and the in-memory run-status cache (1s TTL with backplane invalidation). The global concurrency cap also stays per-replica - operator math is documented in the runbook.
The demo stack
examples/cluster/ in the repo ships a one-command reproduction of the screenshot. docker-compose.cluster.yaml brings up two loomcycle replicas, a Postgres, and an nginx load balancer in front:
cp examples/cluster/.env.example examples/cluster/.env
# edit: LOOMCYCLE_AUTH_TOKEN, POSTGRES_PASSWORD, and one provider key
docker compose -f docker-compose.cluster.yaml \
--env-file examples/cluster/.env up -d
# verify the four cluster invariants
./examples/cluster/verify.sh
# fire 6 runs (alice + bob × quick + medium + long) at the LB
LOOMCYCLE_AUTH_TOKEN=... ./examples/cluster/run-agents.sh
# open the Web UI to see runs distributed across replicas
open "http://localhost:18080/ui?token=$LOOMCYCLE_AUTH_TOKEN"
The verify.sh script exercises four cluster-mode invariants: both replicas register heartbeats, cancel broadcasts reach the owning replica, status queries resolve cross-replica, pause/resume is cluster-wide. The runbook in docs/MULTI-REPLICA.md covers the operational shape - pool sizing, rolling upgrade, crashed-replica recovery, sharp edges.
The Web UI gained a small but useful surface for this release: a replica-a/replica-b chip next to each running agent, with a deterministic hash-derived background so different replicas are visually distinguishable without an ever-growing color table. Single-replica deployments stay uncluttered - the chip is suppressed entirely when LOOMCYCLE_REPLICA_ID is unset.
What's still ahead before we tag v1.0
The architectural pieces are in. The runtime has shipped through each phase as its own release, the cluster demo reproduces the screenshot in five minutes, the operator runbook is written. But "the multi-replica code exists" is different from "v1.0 is ready," and the gap is three pieces of work:
- Load testing at scale. The unit tests cover the invariants; the docker-compose demo exercises the happy path. Neither tells us how the runtime behaves at 100 replicas, 10k concurrent runs, or millions of channel messages. The next stretch is a sustained load run on the actual primitives at production-scale traffic shapes.
-
Functionality testing across the cluster matrix. Every existing feature has been verified single-replica; many have been verified two-replica via
verify.sh. The full matrix - N≥3 replicas × rolling upgrade × crashed-replica recovery × pause-during-fanout × all the substrate primitives × every wire surface - is a wider sweep than what's covered today. Some of it will surface bugs. - Hardening against the cluster invariants. The unit-test suite is green; the parallel code review caught the obvious cluster-correctness issues during each phase's PR. But there are classes of bug - race conditions across LISTEN/NOTIFY delivery, advisory-lock contention under sustained load, dead-replica reaping under partial network partitions - that don't show up in the unit suite and need a hardening pass before a v1.0 tag is responsible.
The honest framing: v0.12.x → v1.0 was always going to be a stretch with two distinct phases - building the multi-replica code, then hardening it. We're done with the first. The second is what comes next. The v1.0 tag is the artefact that says "we believe this is production-ready", and that belief needs evidence we don't have yet at the load shapes v1.0 implies.
Single-replica loomcycle is unchanged and remains production-quality - JobEmber.ai has been running it daily for months. Multi-replica is the thing the load testing applies to, and it's the thing v1.0 is gating on.
What this unlocks even before v1.0
Three operator stories that were uncomfortable to tell with single-replica loomcycle and are now possible:
- Rolling upgrade with zero dropped runs. Pause one replica via the cluster-wide pause, drain its in-flight runs, upgrade, resume; do the same to the other. The pause + snapshot machinery that shipped in v0.8.17 was the precondition; multi-replica is what makes it useful.
- Horizontal scale beyond what one Go process can serve. Production VMs today run loomcycle at ~89 MB RSS / 512 MB cap; one binary on one box served us for months. Provider-concurrency limits or MCP stdio child slots can still cap throughput at higher scale; cluster mode is the exit door.
- HA story for the deployment shape the consumers expected. Every commercial consumer - n8n integrators, JobEmber.ai, external evaluators - assumed "Postgres + N stateless replicas behind a load balancer" was a deployment shape loomcycle supported. It is now. MULTI-REPLICA.md is the operator runbook for that shape.
Companion writeup: When the agent is in one container and its definition is in another covered the substrate (AgentDef / SkillDef / MCPServerDef) that this multi-replica work sits on top of. Substrate state is shared by Postgres rows; the multi-replica work is what makes the runtime around it cluster-aware.
Next blog will be about the load-testing and hardening phases that come between here and the v1.0 tag - what shapes of failure the cluster-mode primitives actually exhibit under sustained load, which sharp edges the unit suite missed, and what gets reinforced before we cut the v1.0 release. The fun part of distributed systems is that the bugs only show up when the boring tests do.